November 7, 2007
I’ve been asked many times (by web designers) about what programming language they should learn so that they can build database driven websites. My short answer is of course: PHP.
That said, I felt a little more detail was required: why do the competing technologies (ASP, ASP.NET, Ruby etc …) suck compared to PHP … in that regard?
From the article:
The article’s title (I admit,) will get some people little miffed at me. But, what can I say, the truth hurts!
Seriously, this statement is valid and is worth talking about because there are a lot of web designers out there who are considering the leap into building dynamic (database driven) web applications. And with so many choices (ASP, ASP.NET, Ruby etc …) it can be very frustrating when trying to make that choice.
Of course, I believe (and know) that PHP is the choice language/technology for web designers. But why are the other technologies not a good choice for web designers?
You can read the rest at killerphp.com:
Why ASP, JSP and Ruby suck for web designers
Thanks,
Stefan Mischook
www.killersites.com
www.killerphp.com
read more
January 20, 2007

Hi,
A little while back I asked my brother (a big Java nerd) to explore using Ruby to rewrite a threaded Java web application – a site monitor.
The results have been really cool so far. So cool in fact that I asked him to write an article on his experience.
NERD ALERT: This article is written for programmers.
–
Writing a standlone, threaded application using Ruby On Rails
By Richard Mischook
Awhile back I wrote a Java application designed to monitor web sites to ensure they are up and running. The Site Monitor service is hosted on the web and allows a user to sign up and add a site to a database that is routinely monitored by the engine.
When the engine finds that a site is down, a log entry is made and the owner is sent an email letting them know that they might want to look into it; if and when the site is back up, another log entry is made and once again the owner is emailed.
The development of the application took a little longer than expected and alas, has had a number of teething pains. On more than a few occasions we have asked ourselves if another set of implementation choices might have been better, such as a technology other than Java.
In addition, rather than delivering the tool as a hosted service, would it make sense to deliver some sort of standalone application that a user could download and run on their own desktop?
Around the same time I had been messing around with Ruby On Rails which as many of you will know, is a web application framework build on the Ruby scripting language. One of the central promises of Rails is a framework that allows the delivery of powerful results quickly.
The questions then:
- Could the Site Monitor be delivered using Rails and if so;
- How long would it take and would it be better than the existing solution?
Requirements
The Java version of Site Monitor is actually reasonably sophisticated and supports a range of features which I will not exhaustively list here.
Instead lets look at the main features we wanted to see in the Rails version:
- Support for multiple sites checked concurrently, with sites double or tripple checked to make sure they were really down.
- Support for multiple control sites to verify that the internet connection to the outside world is up
- Support for multiple notification email addresses and mobile phone numbers (for SMS notification)
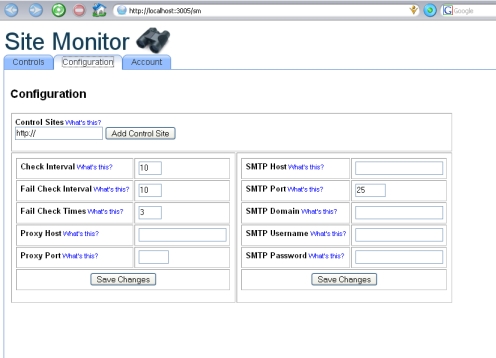
- Configurable by the user with the choices saved to a file that is loaded when the engine is re-started
- An Ajax-based user interface allowing the user to a) configure the engine and b) capable of displaying engine activity
- An easy to install application suitable for Microsoft Windows users.
An example of the user interface can be seen in the screen shots. The web interface leverages the Ajax support built into Rails and allowed me to deliver a richer user interface than normally found in traditional web applications
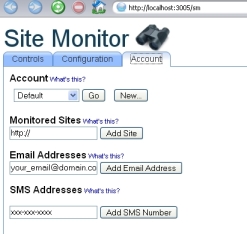
In fact as I’ll show later, some limitations in the Ruby threading model made it necessary for me to use the Ajax support in a way that I had not originally anticipated.
The hardest requirements to fulfill were going to be the first and the last:
i) support for concurrent checking and ii) an easy to install application.
Most of this paper will be about how I tried to address the first requirement, but I will discuss the second as well.
Concurrency in Ruby
In the original Java version of the application, a timer ran from time to time (say once a minute) and invoked a method to load a list of sites to check from a database. A Java thread was retrieved from a thread pool for each site that required checking; this meant that more than one site could be checked at a time.
This was important because it might take awhile to finish checking a site since we were actually double or tripple checking sites that did not respond (in order to avoid false positives). Without threads, it would take significantly longer to check a stack of sites as each site would be required to wait in line (so to speak) to be checked.
The good news was that Ruby has a threading model and it seemed very easy to implement. The check_sites method below (which is abbreviated for clarity) illustrates the main logic which is essentially:
- for each site (line 2), spawn a thread (line 3) and execute the block of code from lines 3-17
- check the site (line 5)
- if the site does not respond (line 7) and we have verified count number of times that the site is down, let the user know (line 11)
-
1 def check_sites(sites)
2 sites.each do |site|
3 threads < < Thread.new(site) { |mySite|
4 begin
5 ping_site(mySite) # actually ping the site
6 handle_up(mySite, ...) # site is up so let user know IF site was down before
7 rescue ConnectException => c #if here then no response
8 count = count - 1 #count is set to some value above (not shown)
9
10 if count == 0 #log it and send mail
11 handle_down(mySite, ...) #another method that logs and sends email not shown here
12 break;
13 else
14 #check control sites [not shown]
15 end
16 end
17 }
18 end
19 threads.each { |aThread| aThread.join }
20 end
-
Note that there are few key bits missing from the above so don’t expect it to run by itself. That said the principle is sound and means that given an array of sites to check, processing will happen concurrently. But there is an issue that I did not anticipate: any code calling this method will block until all the child threads created in check_sites are done. This is a problem because what I had planned was to define a method like the following:
1 def start_engine
2 # load some sites ...
3 while(true)
4 sites = ... #not shown - code to load sites
5 threads = []
6 threads < < Thread.new(sites) { |mySites|
7 check_sites(mySites)
8 }
9 threads.each {|t| t.join}
10 sleep(30) #sleep for 30 seconds
11 end #end of while loop
12 end
The start_engine method starts a loop that:
- Loads a list of sites to check (line 4)
- Creates a new thread and calls the check_sites method with the sites (lines 6 and 7)
- Goes to sleep for 30 seconds (line 10)
The plan was for the sleep() call to happen immediately after calling check_sites but before all the checking was done, i.e. not block. Unfortunately Ruby doesn't work that way; in fact what actually happens is that the call to sleep() only happens after all the threads in check_sites have finished executing.
The other really big problem is that since the while loop is always running, the Rails server (e.g Webrick or Mongrel) is always blocked meaning it cannot serve any further requests - such as my web browser Ajax call to find out the current status. All of this meaning that I needed another way to do the job done by start_engine, i.e. another way of periodically calling check_sites.
You may be wondering why I wanted to run this in a Rails server at all? One answer is that I wanted to do the user interface as an Ajax-enabled web page but also wanted the user to be able to start the server and have the engine running in the background. Alas this was not going to work.
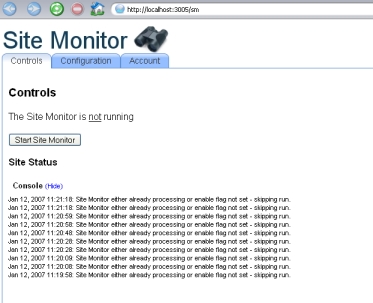
I thought for a second that I might need to think about spawning some seperate processes (rather than relying on Ruby threads), but that looked like a lot of work. I did look at using the backgroundrb library (a Ruby library for simplifying distributed, interprocess communication) but it is not supported on Windows (crappy toy operationg system *&&^%$). Instead I decided a compromise was in order.
Using Ajax to Run the Engine
The problem then: how do I replace the start_engine method such that I can get the server code to periodically check my sites (while allowing other stuff to work)? Well the answer simply enough was to embed a Rails periodically_call_remote tag in my index.rhtml page; the tag sends an Ajax request every so often to the server that gets it to call check_sites. In fact I also embedded a second periodically_call_remote tag that refreshes the user interface console so the user sees what is going on.
There is still a problem though: check_sites can still take some time if you are checking more than one or two sites and any fail to respond. While this is happening (the checking), the Rails server will be unable to answer any UI refresh calls (coming from the second periodically_call_remote tag). Still, not the end of the world as this version is meant for a single user checking a very small number of sites. On the other hand frankly, this is not the most elegant solution and one I would like to change.
In fact I did look at trying to spawn the Monitor in a seperate process using a fork call. Unfortunately the implementation on Windows is broken (anyone see a theme developing here?) In fact the Programming Ruby book's section on processes does suggest that support for forking is limited, which is better than the API documentation's thunderous silence on the matter.
Lesson then: Ruby is Unix-centric by default - live with it.
I did try and get around it by installing a set of gems associated with the Win32 Utils project - specifically win32-process. I did have some luck with this but not enough (the main issue having to do with class loading woes).
I do think that there is some potential in this route, but it would require me to spend a bit more time making sure the Monitor code is free of any Rails dependencies. In the meantime my next little project may be to start playing with win32-process to see if I can get it to work the way I think it should work.
Packaging Up the Whole Thing
I mentioned earlier that one of my other requirements was to try and package this thing up in such a way that I could distribute it as a single, easy-to-use windows exe or equivalent. What I was in fact hoping for was the ability of users to download the whole thing without having to install Ruby or Rails or any of the gems used by the application.
Now admitedly this was something of a tall order; but I was led to believe that it was worth looking at given an article entitled Distributing Rails Apps: A Tutorial.
Unfortunately my attempts have not met with any success; in fact when running the various tools I'm not really getting any feedback that indicates what, if anything went wrong, other than the fact that things just are not working (to be fair I only spent about 15 minutes on this). So I have added this to my list of things to look into; in fact it's top of the list since not getting this working will make distribution that much harder. I'll post a follow up if I have any luck on this front.
Conclusions
The application I re-built in Ruby actually works pretty well and the Ajax user interface does what I hoped it would do - even if it doesn't win any beauty contests. But Ruby threading, while easy to implement, suffers from a few limitations such as:
- When spawning new child threads, the parent thread needs to block waiting for all the little kiddy threads to do their thing.
- This is made even more of a pain by the fact that the main Rails runners, Mongrel and Webrick, can only handle one request at a time - period. It would be nice if someone could write an easy-to-use proxy that wraps a couple of Webrick/Mongrels so that you can have a single container that supports concurrent requests (yes I know you can do this with Apache but that requires that I do some work when all I want is a development environment that can support say - 2 concurrent requests).
Which brings me to another issue with Rails in general that has nagged at me: its reliance on process-based request handling. Each request has to be handled by a dedicated process which would seem to have the potential for limiting the scalibility of a Rails application.
Now I know that this debate has been raging elsewhere on the Interweb and I must confess I have not looked into it in great detail. At the very least it would suggest to me that anyone designing a Rails application really does need to keep that in mind, especially with regard to managing connections to databases. While that's a side issue, I invite any comments (and pointers) on the matter.
One last thing - my main interest in Rails has been fueled by my ever increasing lack of patience. Not so very long ago I was happy to spend days trying to understand some new API or product that promissed to be the next cool thing. This, some might say, was a prerequisite for becoming a Java J2EE developer.
These days, I have a wife and a baby, TV shows I want to watch, books I want to read - in other words - lots of other things I want to do. I want to get my work done NOW. I want to work with tools that are enablers - rather than impediments.
We're not there yet and truth be told, Rails is very good for developing data-driven green field web applications; but there are limits to what it can do and one wonders if it can (or indeed should) grow beyond these.
References
Programming Ruby: The Pragmatic Programmers' Guide, Dave Thomas
read more



